“There is a theory which states that if ever anyone discovers exactly what the Universe is for and why it is here, it will instantly disappear and be replaced by something even more bizarre and inexplicable. There is another theory which states that this has already happened.”
― Douglas Adams, The Restaurant at the End of the Universe
This blog post is a walk-through of how I do red team operations, today. I’ll take you through the primary tools and tactics I use for each phase of a simulated attack.
Assume Compromise
When I play red, it’s usually with a team tasked to work as a representative adversary in a compressed time frame. Things that might take months or a year as part of a real-world campaign have to happen in a few weeks or days. The purpose of these engagements is usually to train and assess security operations staff.
In a compressed adversary simulation, it’s common to white card access. Sometimes, a trusted agent opens every link or file the red team sends. Other times, the red team gets remote access to a few systems to serve themselves. This is the assume breach model and I’m seeing a lot of internal red teams adopt it for their activities.
While the engagements I do now are almost always assume compromise, I feel it’s important to have the capability to execute a campaign, beginning to end. Cobalt Strike will always contain the tools to execute a targeted attack process and get a foothold in a production environment.
Initial Access
Assume Compromise gives a red team a cooperative insider. It does not defeat static defenses. Red Teams still have to worry about anti-virus, egress restrictions, application whitelisting, HIPs, and other measures.
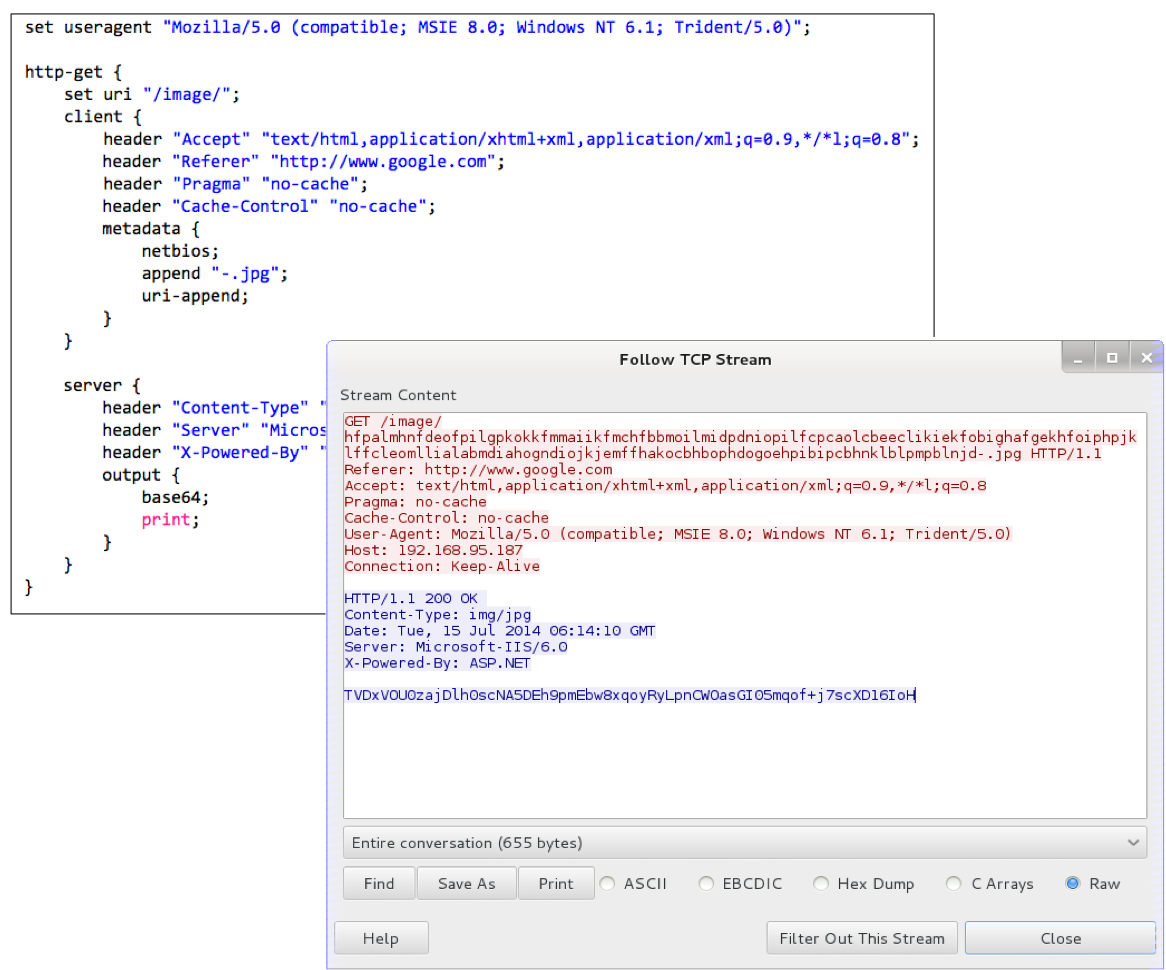
For my initial access I get by with one of Cobalt Strike’s user-driven attacks. Sometimes I’m lucky and a zipped executable is enough to start with. The Java Applet Attack is still a favorite. It’s helpful to download the Applet Kit and sign Cobalt Strike’s Applet Attack with a code signing certificate. I also lean heavily on the Microsoft Office macro.
When these fail me, I often resort to the HTML Application Attack. More and more, I’m finding that I have to modify the HTML Application Attack, on the fly, to run a PowerShell script rather than drop an executable. Using my tools in an engagement helps me understand which features provide value to a red team and which need improvement. As a developer, I understand my toolset’s strengths and shortcomings really well.
My initial access payload is always a Beacon of some sort. The HTTP and HTTPS Beacons are my workhorse. When HTTP Beacon is run as a user, it’s well equipped to defeat most egress restrictions. I use Malleable C2 to tweak my Beacon User-Agent and other indicators to something that will pass through a conservative proxy configuration. I fall back to a DNS Beacon with its DNS stager when I can’t egress with an HTTP Beacon.
Privilege Escalation
Once I have a foothold, my first goal is to elevate privileges. In a situation with fully patched systems, I run harmj0y’s PowerUp script. The PowerUp script is good at finding misconfigurations that I can act on for elevated rights. Beacon solved the PowerShell weaponization problem last year and it’s a wonderful agent to use offensive PowerShell capability with.
Recently, I was in a situation where the operating systems were held back to an older patch level. We had an opportunity to elevate with a Metasploit Framework local exploit–assuming we could get a Meterpreter session. More and more this is not a given for the situations I see. Our way around this was to port the needed Metasploit Framework local exploit to a stand-alone executable and use it to elevate. [Note: This wasn’t a refusal to use Meterpreter. It was simple fact–we couldn’t.]
If I know credentials for a local admin, I will use Beacon’s runas to run a Beacon as that user. I added runas to Beacon in January and this command is pure gold. I’ve gotten use out of it many times. [It beats doing this. See pg. 31, Red Team Field Manual]
Bypass UAC deserves an honorable mention too. If the current user is a local admin, Beacon gives me this option to spawn a Beacon into a high integrity process. I almost always run whoami /groups, right away, to see if this is an option.
Harvesting Credential Material
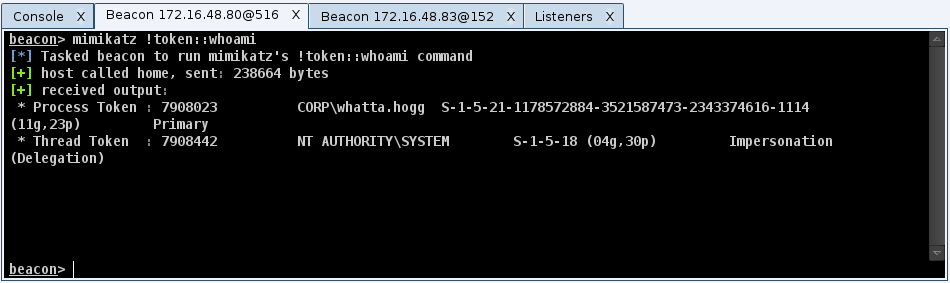
Once I elevate, one of my first priorities is to move away from patient zero (the initially compromised system). My options to move are dictated by the trust relationships I have access to. Now that Beacon has hashdump and wdigest, I run these commands as soon as I have the necessary privileges. Before Cobalt Strike 2.4, I would use PowerShell to run PowerSploit’s Invoke-Mimikatz cmdlet. I also use ps to see which processes are running as users other than my current one.
Lateral Movement
I think of lateral movement in four steps. First, I need to find my potential lateral movement targets. Next, I need to make use of an available trust to assume an identity that may give me rights on a remote system. Next, I check whether or not my remote target sees my current identity as an admin. Finally, I use my validated trust relationship to get remote code execution.
To discover targets, I use Windows net commands and I make heavy use of PowerView. PowerView is a very powerful tool, but it has a learning curve. I’m slowly transitioning my process to its capabilities.
To assume an identity as another user, I usually try to steal an access token from another process. If I know credentials, I use net use to connect to C$ or admin$ on a remote system. Now, I also use runas to spawn a Beacon running as the user whose credentials I know. This gives me flexibility that a net use does not. If I have a golden ticket, I run kerberos_ticket_use in Beacon to add it to my Kerberos tray. If I only have hashes, I try Mimikatz’s sekurlsa::pth command to spawn a Beacon with a token that passes the username and hash I provide. I’m still working to make this method of pass-the-hash a seamless part of my process. YMMV.
If it’s possible to meet my objectives without putting a Beacon onto a target, I do so. If I decide a Beacon is the right way to go, I export it as some sort of artifact. I upload it to the host that holds my assumed identity and I copy my artifact to the target system.
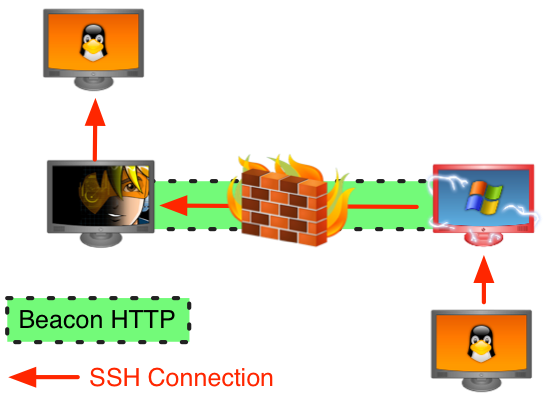
For lateral movement, I almost always use Cobalt Strike’s “stageless” SMB Beacon as my payload. This allows me to control compromised systems over a named pipe. All egress happens through the Beacon I link to other Beacons from. Named pipe communication is encapsulated within the SMB protocol. This method of communication with compromised systems is very stealthy. It’s also great for controlling systems that can not egress.
To execute my payload, I rely on native tools. I use wmic, at, sc, schtasks, and PowerShell’s Invoke-Command to run things on remote targets. I like having multiple options for remote code execution. I do not assume that I will always get to remotely manipulate the service control manager. I really want a bumper sticker that says, “Lateral Movement: It’s more than just PsExec”.
Pivoting
While I operate through Beacon and think a lot about Windows systems, this isn’t the whole game. It’s important to pivot other tools into a target environment and use these to interrogate, attack, and conduct post-exploitation on other systems.
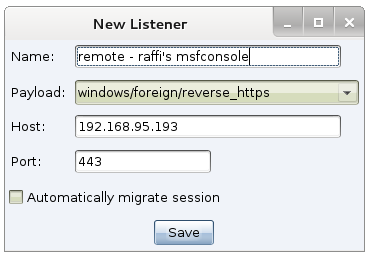
Before I pivot, I usually inject a Beacon instance into another process and have it call back to separate infrastructure with different indicators. I consider these Beacons OK to sacrifice. Next, I speed up the new Beacon so it communicates interactively with its command and control server. Interactive communication is a recipe to get caught, that’s why I like to limit it to infrastructure marked for sacrifice.
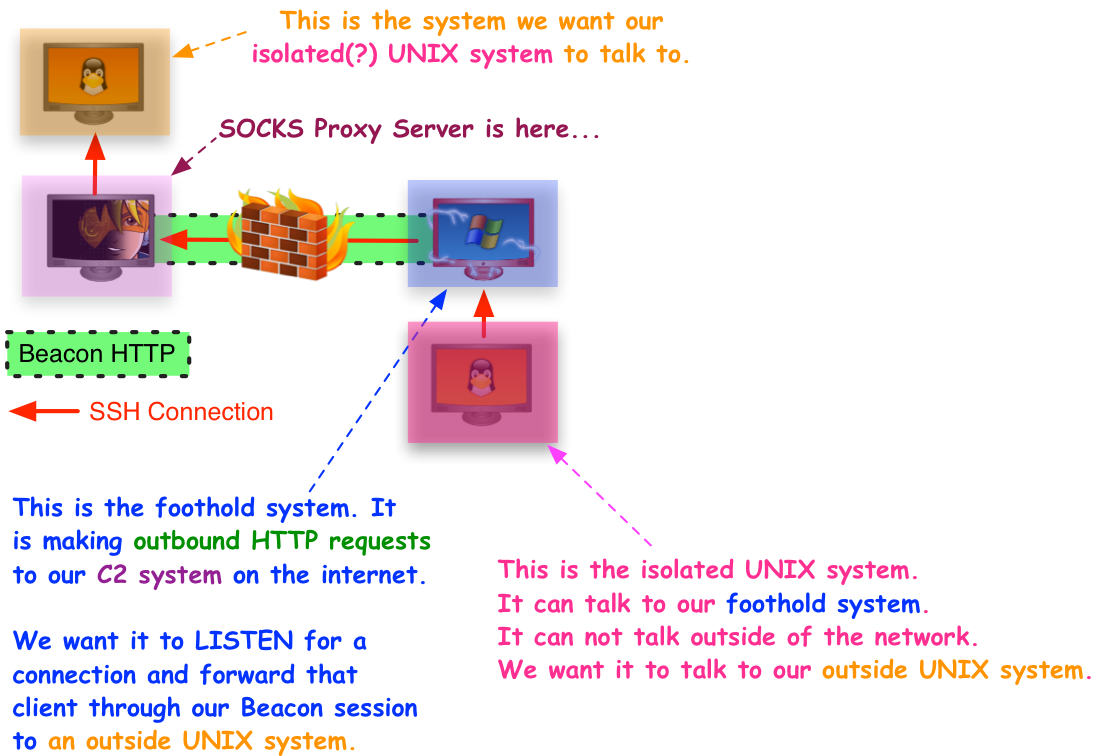
To pivot, I open up a SOCKS proxy server that tunnels traffic through the new Beacon. I then make this SOCKS proxy server available to my teammates who want to use other tools. SOCKS and proxychains are sufficient to get most tools into an environment. Some situations may require a VPN pivot. I can count, on one hand, the number of times I’ve had to use a VPN pivot. It’s nice to have options.
User Exploitation
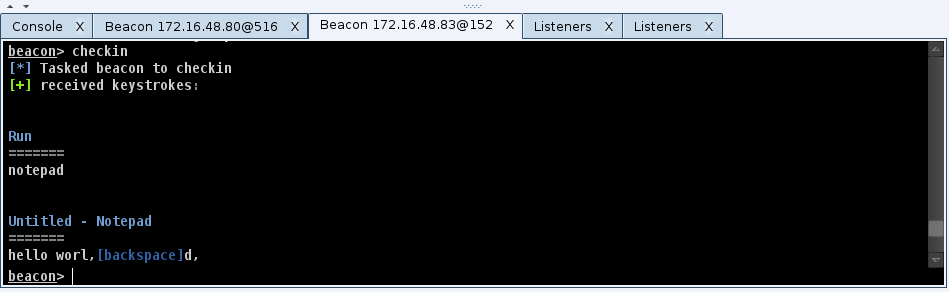
Once I have my footholds in a network and control the other systems I find interesting, the next step is user exploitation. Notice, I didn’t say post-exploitation. There’s a reason for this. Beacon and other agents are good at post-exploitation. They allow a red team to interact with and control compromised systems with the ease a system administrator might enjoy.
User exploitation is observing the user’s activity, identifying a target of opportunity [possibly time limited], and acting on it.
Riddle me this Batman… let’s say you control thirty, forty, or more workstations–with active users. How do you know what is happening on each of those workstations at any given time? How do you keep this knowledge of what’s happening fresh without giving up your presence to a watchful defender? How do you watch these systems with limited resources on your red team?
The answer: Today’s tools, including mine, were not built with this problem in mind. I’m working to remedy this and Cobalt Strike 2.4‘s refactor of Beacon features into jobs was a first step. Expect more to come on my end.
What’s next?
You’ll notice, the process in this blog post is similar to what I teach in Tradecraft. You’ll also notice that the execution is different. The methods in this post were, for a long time, my fallback way to operate [see #4]. Sometime last year, Beacon hit a tipping point, and this has become my primary way to use Cobalt Strike. This style of hacking is what I teach in Advanced Threat Tactics today. The Veris Group’s Adaptive Red Team Tactics course is similar in mindset too. The demonstrated advantage of these new school red team tactics have forced me to re-think my tool’s dependencies, workflows, and user experience. These are interesting times.



{kind=link}